
.png)
Deploying AI models into air-gapped or customer-managed infrastructure introduces a unique set of challenges—especially when those models include massive, resource-hungry large language models (LLMs). During a recent conversation with Tom Kraljevic, VP of Customer Engineering at H2O.ai, he walked us through their self-hosted architecture and offered a clear-eyed perspective on best practices for model distribution in such environments. In this blog, we’ll first walk through H2O.ai’s unique architecture for distributing open-weight AI models to their customers. Then, we talk through best practices their team learned designing this architecture, and what lessons you can adopt going forward as you build or improve your own.
H2O.ai’s Self-Hosted Model Serving Architecture
At a high level, H2O.ai’s architecture reflects a clear separation between model artifacts and serving infrastructure. Their goal is to make the platform deployable in entirely offline environments without compromising on performance or flexibility.
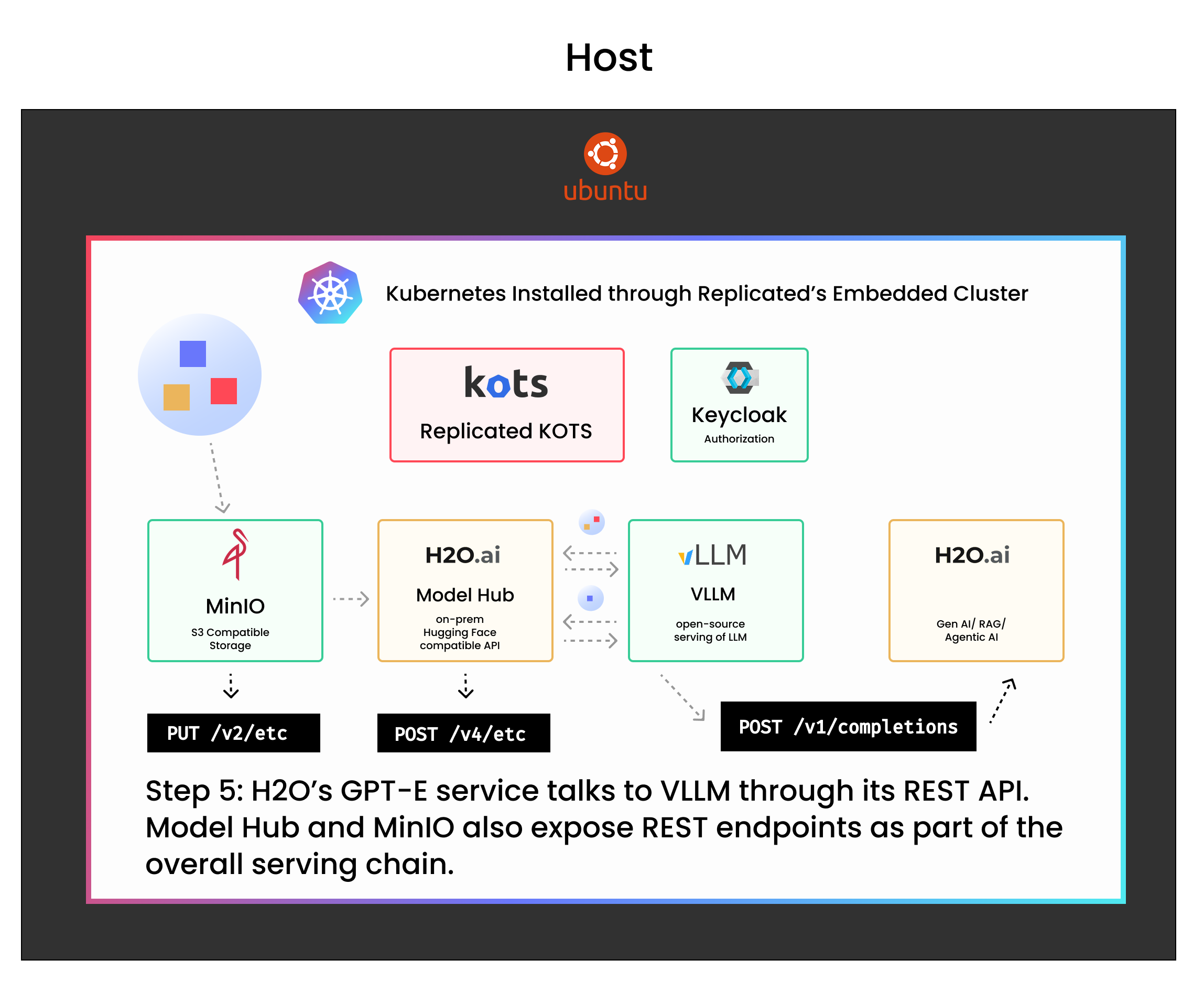
The architecture consists of seven key components:
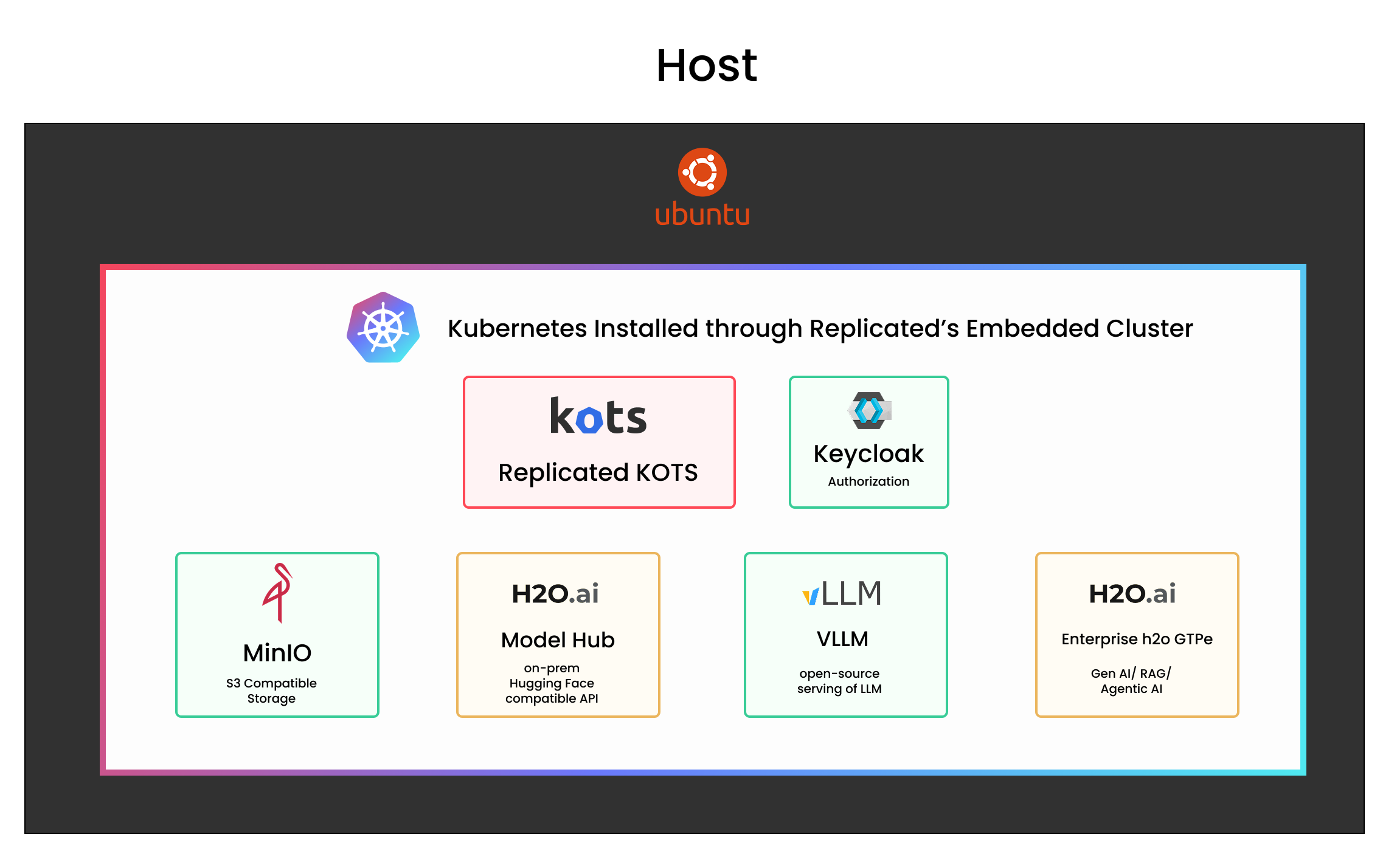
- Replicated Embedded Cluster: a self-contained Kubernetes environment installed on the host machine, used to run all application components without requiring a pre-existing cluster.
- Replicated KOTS: a service deployed within a Kubernetes cluster that manages application components—including model serving endpoints, authentication services, and auxiliary infrastructure—by coordinating containerized workloads, mounting configuration, and handling deployment lifecycles, typically via Helm-based installs wrapped by Replicated.
- Keycloak (authorization mechanism): Keycloak is an open-source identity and access management service that runs inside the Kubernetes cluster to provide authentication and authorization, typically handling login flows, token issuance, and user management via OAuth2/OIDC protocols for internal services.
- MinIO Object Storage: an open-source, S3-compatible object storage service used within the Kubernetes cluster to store large model artifacts (e.g. LLM weights) and other static assets, enabling local, high-throughput access for services like Model Hub and VLLM in air-gapped or self-hosted environments.
- H2O.ai’s Model Hub: an H2O.ai built internal service that exposes a Hugging Face-compatible REST API for serving LLMs via VLLM, acting as a lightweight layer that maps model requests to S3-compatible object storage (e.g. MinIO) and handles loading, caching, and routing of model artifacts within the Kubernetes cluster.
- VLLM Model Server: a GPU-optimized model server that serves LLMs via Hugging Face APIs, loading weights from local object storage for efficient, high-throughput inference inside Kubernetes.
- H2O.ai’s Enterprise GPTe: an internal service that provides agentic and RAG-based LLM capabilities, interfacing with VLLM-backed models through a local REST API within the Kubernetes cluster.
The following steps explain how Tom and his team deploy large models within this architecture:
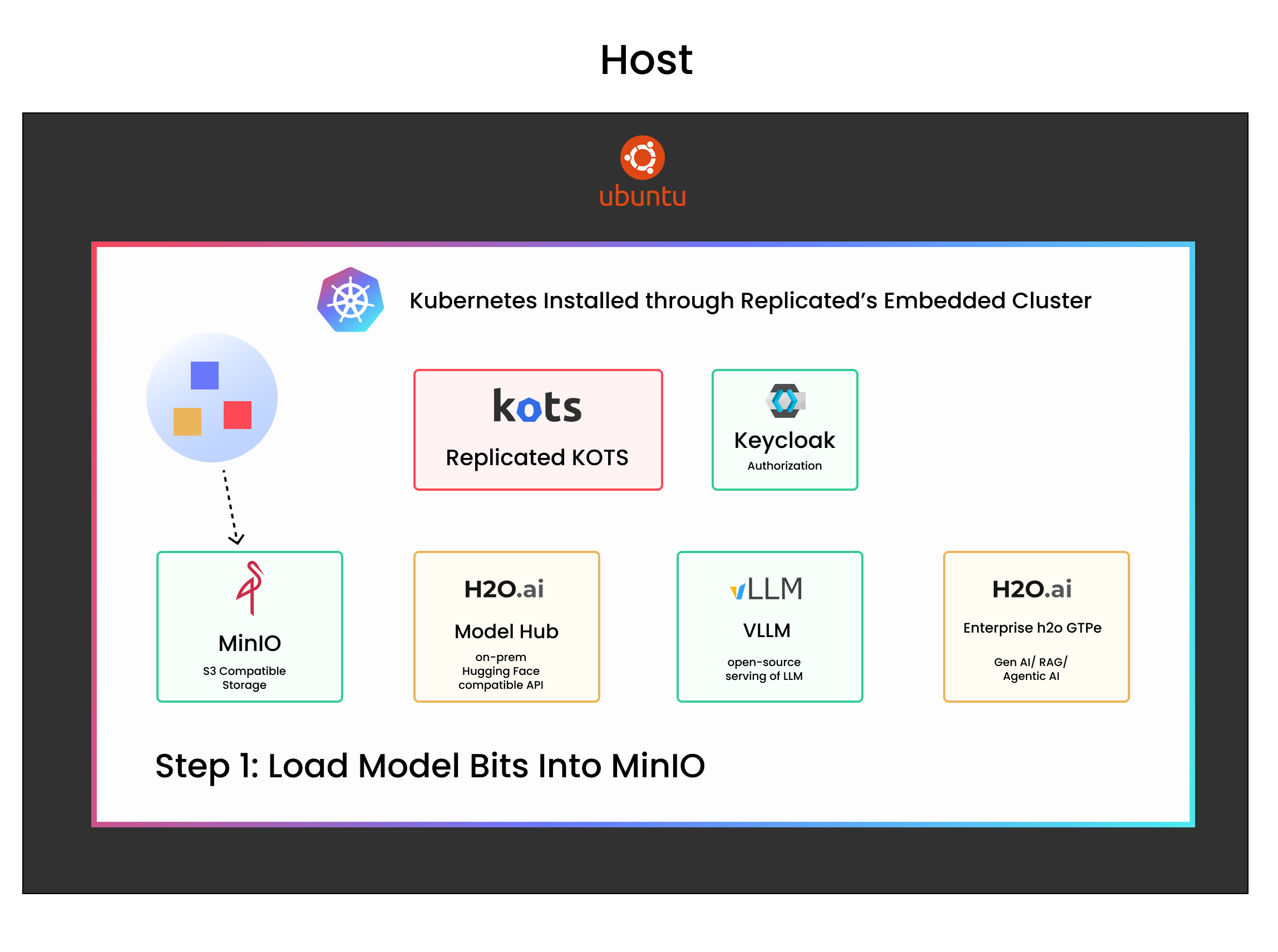
- Load model bits into MinIO
Use the MinIO client (mc), a Linux command-line tool, to point to your local directory of model files and upload them into MinIO. This sideloads the model bits directly into object storage (read more about why sideloading is important below).
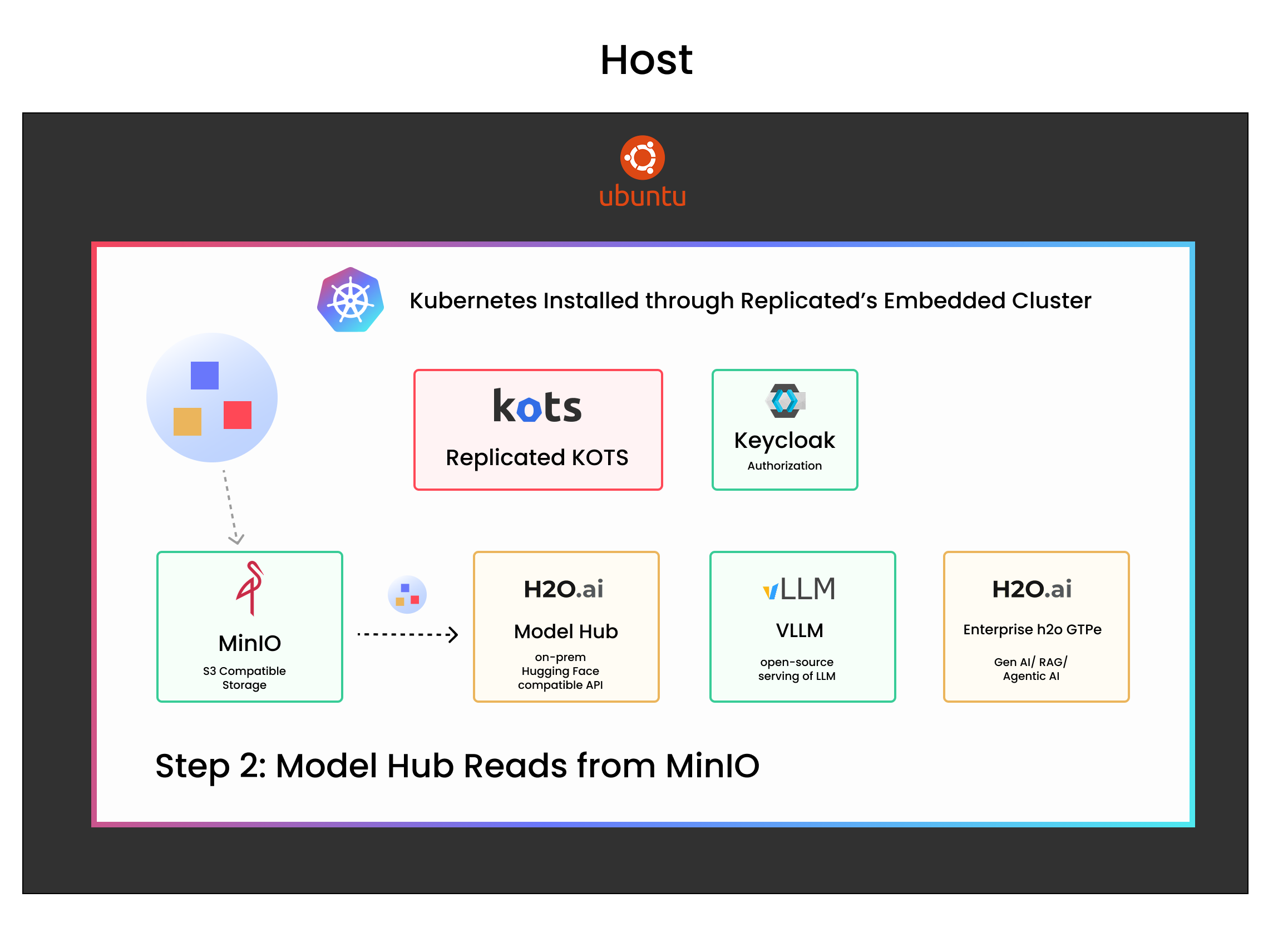
- Model Hub reads from MinIO
Model Hub is configured to read model files from MinIO. It exposes a Hugging Face-compatible REST endpoint for downstream components.
- VLLM reads from Model Hub
VLLM is configured to communicate with Model Hub. It fetches model files as needed and prepares them for inference.

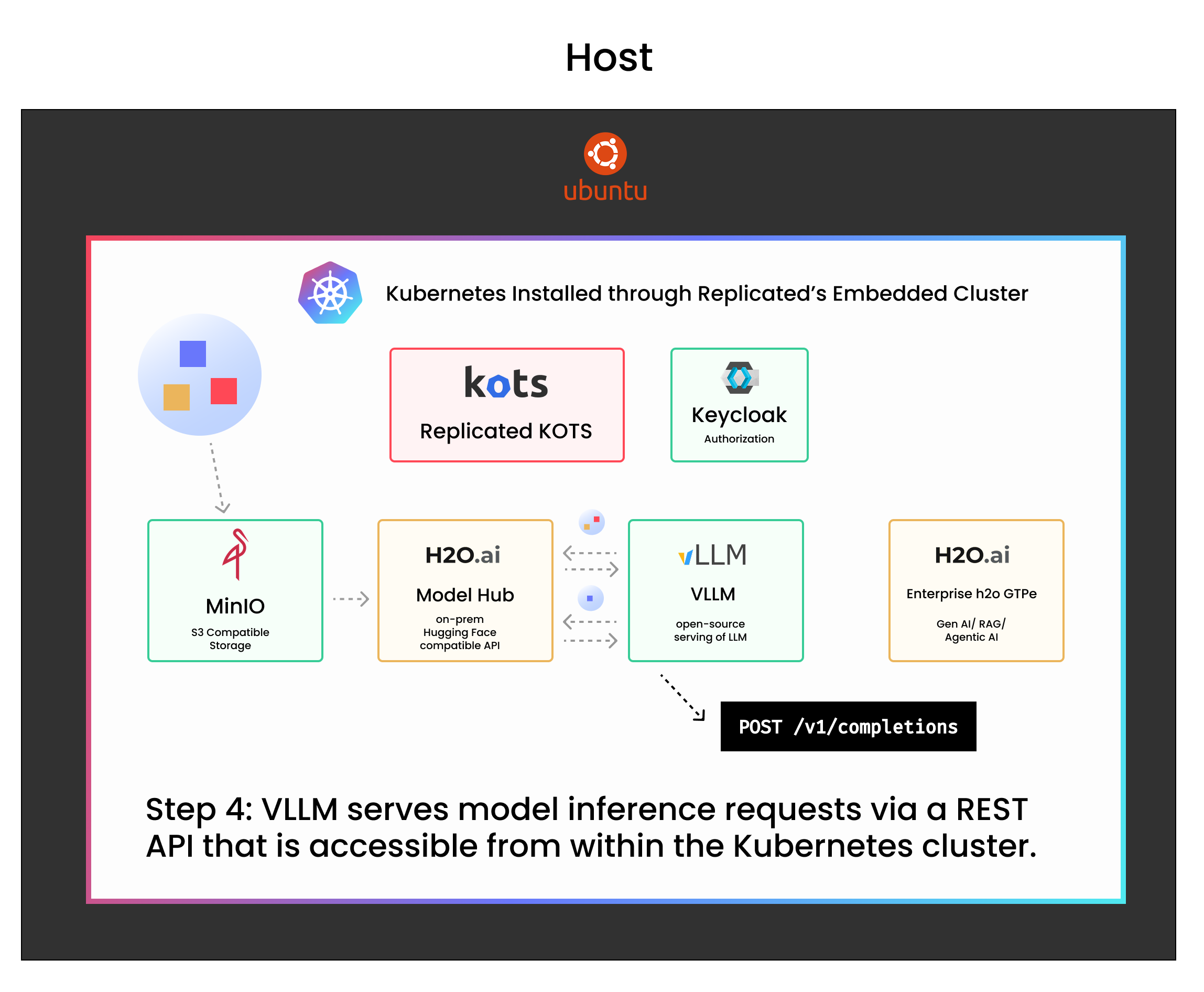
- VLLM exposes a REST endpoint
VLLM serves model inference requests via a REST API that is accessible from within the Kubernetes cluster.
- GPT-E connects to the REST endpoint
H2O’s GPT-E service talks to VLLM through its REST API. Model Hub and MinIO also expose REST endpoints as part of the overall serving chain.
The key step in this process is taking model files—typically sourced from Hugging Face—and sideloading them into MinIO using the mc CLI. The models are bundled as tar files, since the individual files are under 10 GB but collectively are very large. To avoid container registry bloat and simplify deployment, these models are not packaged into Docker images.
While this architecture is designed to work entirely offline, H2O.ai also supports a range of flexible deployment options for customers with different preferences or existing infrastructure. “Instead of pointing to a locally hosted VLLM, you could point to a VLLM somewhere else—or just use a cloud-based service like OpenAI or Anthropic,” Tom noted. Similarly, customers can swap out the default S3-compatible MinIO bucket for their own managed object storage. “We have a number of customers who like to swap in their own homegrown storage solutions,” Tom explained. This flexibility is enabled by the choice to store model data in S3-compatible formats. Because S3 is widely adopted in enterprise environments, it offers both portability and integration ease—allowing customers to move storage out-of-cluster or plug into existing infrastructure without friction. For H2O.ai, this was a key reason to favor S3 over container registries for model artifact storage.
This setup allows H2O.ai to deliver a powerful and flexible stack into customer environments—whether connected or completely air-gapped.
“It’s a great way of being able to show to the customer: we can give you this capability. It’s fully air-gapped—no need to reach the internet to do anything once you’ve copied over your bundles of assets,” Tom explained.
This architecture isn’t just technically sound—it reflects the hard lessons H2O.ai has learned from delivering LLMs into demanding enterprise environments. From sizing strategies to sideloading models and handling GPUs offline, their approach offers a clear roadmap for anyone looking to distribute AI workloads reliably into self-hosted or air-gapped settings.
Drawing from this architecture, Tom also shared a set of practical best practices that help H2O.ai deliver reliable model-serving capabilities into self-hosted environments.
H2O.ai’s Best Practices for Distributing Models Into Self-Hosted Environments
1. Differentiate Your Model Sizes—and Strategies
Not all models are created equal. For models under ~1GB, Tom does recommend packaging them directly into Docker containers. “We’ll try to just package it to make it be more tightly integrated with the software versioning... it’s easier to dockerize the applications,” he noted.
But LLMs are a different story. These models often span hundreds of gigabytes, making them unsuitable for container packaging.
“Any model that’s maybe less than a gigabyte, we’ll try to just package it... but the big ones? It’s just not feasible,” Tom emphasized.
As part of the bundling process, they prune extraneous formats, keeping only what’s needed—typically the safetensors files and relevant metadata.
2. Design for Air-Gapped and Internet-Free Environments
H2O.ai designs with air-gapping in mind from the beginning. That means all software and artifacts must be deliverable offline, including drivers and Helm charts.
For GPU support, customers can choose between:
- The full NVIDIA operator, which pulls assets dynamically (requires internet), or
- A pre-installed driver setup, which uses partial operator components to expose GPU scheduling from the host.
“Whatever the customer is able to support with the least amount of involvement from me is the way,” Tom quipped.
3. Use Helm or Replicated for Installation Flexibility
H2O.ai uses Helm as the core of their deployment system, wrapped in Replicated for enterprises that want an intuitive GUI, lifecycle tooling, and Embedded Cluster support. Replicated’s Embedded Cluster provides an all-in-one Kubernetes runtime that simplifies deployment into customer environments with no pre-existing Kubernetes infrastructure.
“We’ve taken our Helm-based install... and just put that inside of Replicated,” said Tom. “Now the Replicated stack is fully integrated with the standard Helm deployment.”
This gives H2O.ai the flexibility to deliver the same experience (and leverage the testing investment) whether a customer is using Helm directly or installing through Replicated's enterprise-grade interface.
4. Avoid Overloading Your Container Registry
Trying to load LLMs directly into your container registry is a recipe for disaster. “You can wait 30–45 minutes, and your reward is an out-of-disk failure,” Tom warned. “That takes out one of the worker nodes in your cluster.”
Instead, always store large model artifacts externally (e.g., in MinIO) and mount them dynamically at runtime.
5. Plan for Fine-Tuning and Model Ownership
While many deployments start with open-weight models, fine-tuning introduces new ownership and security concerns.
“Once [customers] fine-tune a base model on their own data... they’re more interested in protecting it,” Tom explained.
If you expect to support model customization, consider how you’ll handle:
- Version control of fine-tuned models
- Multi-user access and role-based permissions
- Support for model "write-backs" (e.g., for saving checkpoints)
These requirements often evolve quickly as customers go from experimentation to production.
6. Don’t Ignore Model-Serving Parameters
VLLM (and other inference engines) come with dozens of runtime parameters—some of which can drastically impact performance, memory consumption, or model compatibility.
“There’s just a lot of things that you need to be able to optimize... It’s almost like its own whole operating system,” Tom said.
Make sure your deployment:
- Exposes these parameters in a configurable, documented way
- Sets reasonable defaults for context length, kv cache, and batch size
- Provides profiling or logging to help tune performance over time
7. Build a Strategy for Model Updates and Dev/Prod Parity
Many customers will want to test models in a dev environment before promoting them to production. Supporting this requires more than just two clusters—it means enabling safe, repeatable promotion workflows.
“Typically, customers will have multiple environments… the prod environment will move less fast than dev,” Tom noted.
Consider:
- Including environment-aware configuration (e.g., dev/test/prod values.yaml overrides)
- Building CI/CD pipelines that support promoting models across clusters
- Allowing side-by-side deployment of multiple model versions for A/B testing or rollback
Get Started with Replicated
If you’re building an application that needs to run inside customer-managed or air-gapped environments, Replicated gives you the tooling to package, distribute, and operate that software with ease. From embedded Kubernetes to automatic license enforcement and upgrade management, Replicated helps vendors like H2O.ai deliver modern apps into complex enterprise infrastructure.
Explore how Replicated can help you distribute your application today.